Algoritmos de Alocação Dinâmica de Tráfego¶
Para Dynamic Traffic Assignment, a demanda de tráfego é definida em termos de matrizes OD, cada uma fornecendo o número de viagens de cada centroide de origem para cada centroide de destino, para uma fatia de tempo e para um tipo de veículo. Um sistema de escolha de rotas distribui os veículos pelos diferentes caminhos de cada origem para cada destino. A distribuição por caminho dependerá do custo do caminho, que depende do custo de cada link que compõe o caminho. Quando um veículo é gerado em sua origem, ele é atribuído a um dos caminhos disponíveis, conectando essa origem ao destino do veículo. Esses caminhos são calculados quando a simulação começa e recalculados no intervalo de tempo de escolha de rotas.
O veículo percorrerá esse caminho até seu destino, a menos que tenha permissão para atualizar dinamicamente a rota em percurso (ou seja, seja um veículo guiado) e exista uma rota melhor de sua posição atual até seu destino, ou seja desviado por uma ação de gerenciamento de tráfego, ou perca um movimento de conversão devido a congestionamento em simulações microscópicas. Veja mais informações sobre tipos de caminho aqui.
O processo de simulação para a Stochastic Route Choice, baseado em caminhos dependentes do tempo, consiste nas seguintes etapas:
Etapa 0: Calcular árvores de caminhos mínimos iniciais para cada centroide de destino usando os custos iniciais.
Etapa 1: Simular por um intervalo de tempo predefinido (por exemplo, 5 minutos) conhecido como Intervalo de Escolha de Rota, atribuindo aos caminhos disponíveis a fração das viagens entre cada par OD para esse intervalo de tempo de acordo com o modelo de escolha de rota selecionado. Obtenha novos tempos médios de viagem dos links como resultado da simulação.
Etapa 2: Recalcular os caminhos mínimos, levando em conta os novos tempos médios de viagem dos links, e calcular a porcentagem de uso dos caminhos disponíveis.
Etapa 3: Se houver veículos guiados, forneça as informações calculadas na etapa 2 aos motoristas que estão dinamicamente autorizados a atualizar o caminho em rota.
Etapa 4: Vá para a etapa 1.
Esta seção descreve:
- Representação da Rede Viária: Descrevendo como a rede de escolha de rotas é representada.
- Caminhos Definidos: Estes são caminhos fixos fornecidos pelo usuário ou provenientes de outro experimento.
- Funções de Custo de Link: descreve como é derivado o custo percebido de percorrer uma seção viária.
- Caminhos Roteados: Descreve como os caminhos de rota são encontrados.
- Seleção de caminho: Descreve como os veículos escolhem seus caminhos pela rede, incluindo o efeito das informações dos sistemas ITS que fazem os veículos atualizarem a escolha de caminho em rota.
Representação da Rede Viária ¶
O uso de seções e interseções, a representação e o nível de detalhe da rede utilizados para a simulação microscópica, é inadequado para os algoritmos de cálculo de trajetórias. Isso requer uma representação em grafo (links e nós) que considere explicitamente os movimentos de conversão no fim de uma seção e, portanto, o link que conecta dois nós usado nos cálculos de escolha de rota conterá tanto uma seção quanto um movimento de conversão em termos de custo. Para converter de uma representação de seção viária e interseção para links, cada seção viária é dividida no mesmo número de links que o número de movimentos de conversão no fim da seção; a cada link pode então ser atribuído um custo de percorrê-lo, que inclui o custo atribuído à conversão no fim da seção. Diferente funções de custo pode ser usado para um link, dependendo dos custos anteriores disponíveis.
A próxima figura mostra um exemplo de uma rede de tráfego composta por seções e junções. A representação correspondente da rede usada pelos algoritmos de rota, composta por nós e links, é mostrada abaixo dela. Observe que, para cada seção, é criado um nó e há um link para cada movimento de conversão. O custo atribuído a cada link é uma função de variáveis (como o tempo de viagem) da seção mais variáveis do movimento de conversão.
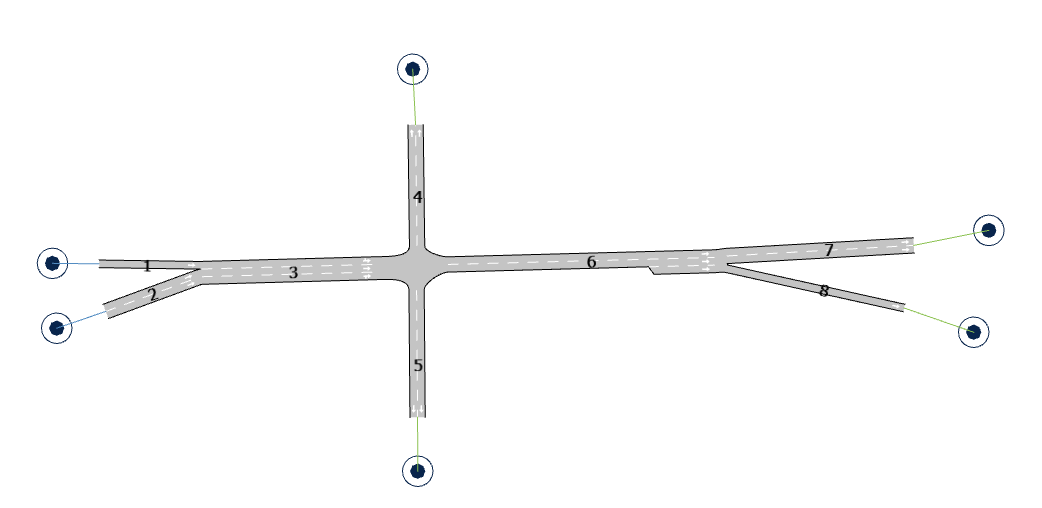
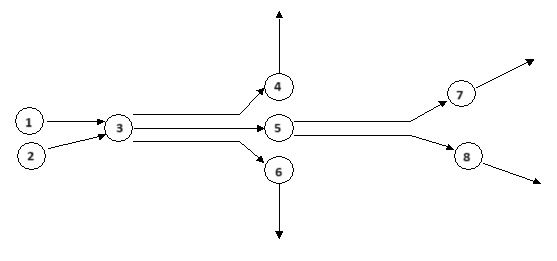
Caminhos Definidos ¶
Os caminhos disponíveis de uma origem a um destino, que são levados em conta no processo de seleção de caminho para o veículo, podem ser predefinidos (rotas definidas pelo usuário ou rotas extraídas de árvores de caminho mínimo calculadas anteriormente, ou soluções completas de escolha de caminho calculadas anteriormente) ou calculados pela aplicação de um algoritmo de caminho mínimo, que usa os conceitos de "custo" e calcula árvores de caminho mínimo.
Rotas OD (anteriormente conhecidas como rotas definidas pelo usuário) correspondem à ideia de caminhos bem conhecidos, ou os caminhos mais familiares para os motoristas, de uma origem a um destino, de acordo com o conhecimento do analista sobre a rede modelada. Elas são predefinidas pelo analista usando o editor de rede ou obtidas como saída de outros simuladores de tráfego ou modelos de transporte, sejam macroscópicos ou microscópicos.
As saídas de Path Assignment são o resultado de uma alocação estática de tráfego (macro) ou de uma alocação dinâmica de tráfego baseada em equilíbrio dinâmico do usuário usando simulação microscópica, mesoscópica ou híbrida. A partir de uma Path assignment, o usuário pode extrair rotas OD específicas ou todo o conjunto de árvores de caminhos mínimos. As Rotas OD são uma lista de links de uma origem a um destino, enquanto as árvores de caminhos mínimos têm uma estrutura que define um caminho de cada link da rede para um destino. As duas estruturas, do ponto de vista lógico, representam um caminho ponto a ponto, mas na primeira representação, Rotas OD, quando um veículo perde um movimento de conversão, ele perde seu caminho e não tem nenhuma outra informação. Com uma árvore de caminhos mínimos, ao contrário, o veículo sabe como continuar seu caminho a partir do novo link.
Os caminhos mínimos são calculados aplicando o algoritmo de caminho mínimo a uma rede representada como links e nós, na qual cada link tem uma função de custo associada que fornecerá o custo usado no cálculo do caminho mínimo.
Funções de Custo de Link¶
Na representação link-nó da rede usada no cálculo das rotas mais curtas, dois tipos diferentes de função de custo são associados a cada link e usados para calcular as árvores de caminho mais curto. Eles são o Função de custo de caminho mínimo K-initials e o função de custo dinâmica. Em ambos os casos, a ideia padrão da função de custo é que ela representa o tempo de viagem do link em segundos, composto pelo tempo de viagem da seção mais o tempo de viagem do movimento de conversão. As funções de custo padrão podem incluir outros termos como custos fixos, e podem ser adicionados custos que dependem da atratividade dos links. Exemplos disso podem ser pedágios ou outros fatores, como o peso psicológico de baixos limites de velocidade.
Os valores de custo do link têm uma faixa de valores possíveis \([1e-06..1e06]\). Todos os valores fora deste intervalo são substituídos, valores menores que \(1e-06\) são substituídos por \(1e-06\) e valores superiores a \(1e06\) são substituídos pelo custo máximo no intervalo multiplicado por 10.
Para cada link, o usuário pode escolher o Função de Custo K-Initials e Função de Custo Dinâmica, e definir uma função de custo padrão do software (selecionando Padrão), ou selecione qualquer outra função de custo definida pelo usuário. Isso é selecionado no editor de movimento de conversão, na caixa de lista Cost Functions da aba Dynamic Models encontrada dentro do Editor de nós. As funções de custo são selecionadas no movimento de conversão, pois o movimento de conversão é o objeto único que diferencia links que compartilham a mesma seção viária.
Observe o Caminho Mais Curto K-Initials funções são usadas somente quando o Caminho Mais Curto K-Initials cálculo é usado.

A lista de funções de custo disponíveis, e como elas são criadas e editadas, é descrita no Seção de Funções de Custo.
Atratividade do Link¶
A atratividade de um link pode ser definida no Editor de nós na subaba Turn, e ela será aplicada a todos os links de roteamento que incluem a seção afetada.
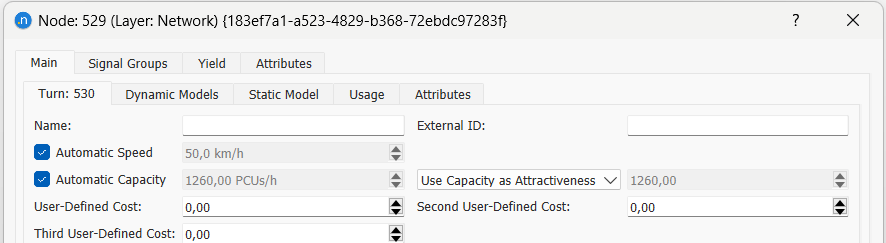
No entanto, a rede pode calcular um valor automatizado de atratividade baseado em vários elementos: a capacidade teórica de fluxo das seções de origem e destino, o número de faixas nas seções envolvidas, o número de movimentos de conversão com a mesma seção de origem e a capacidade teórica de fluxo desses movimentos de conversão.
Uma faixa tem um peso que denota sua contribuição para o cálculo da capacidade de um link. Por exemplo, uma faixa central contribui integralmente para a capacidade de um link, mas uma saída ou uma faixa lateral tem um peso menor. Portanto, o peso de uma faixa (WLi) é definido como 1 para uma faixa central e 0,75 para faixa lateral ou de saída.-tentar atualizar isto com uma imagem?
-A capacidade genérica por faixa em uma seção *s* é, portanto, definida por: <img src="Equations/Images/SRC_GCLs.png" /> onde *C<sub>s</sub>* é a capacidade da seção *s*. -GCL comentado porque não é usado de forma algumaAlgoritmo de Atratividade¶
A atratividade de um link – sendo um link uma seção (s) mais um movimento de conversão (t) – é obtido como resultado de um algoritmo que executa as cinco etapas a seguir:-Usar parte do texto do documento? Acho que fica mais claro?
-
Para cada movimento de conversão considerado, ele encontra a atratividade desejada de cada movimento de conversão que sai da seção de origem s (esta pode ser a capacidade exigida pelas faixas de destino ou a capacidade manual definida pelo usuário em t em si).
Atratividade desejada é a quantidade teórica de atratividade que um movimento de conversão teria if a capacidade da seção de origem (s) era infinita. Mas a capacidade da origem é sempre finita e pode ser menor ou maior que a atratividade desejada. Por exemplo, a seção de destino pode solicitar 1.000 PCUs e a faixa de origem pode ser capaz de fornecer 500 PCUs, ou até 2.000 PCUs.
Nesses casos, o destino receberia 500 e 1.000 PCUs, respectivamente. Isso mostra que a atratividade desejada define o limite superior e a origem fornece tanto quanto pode, até o valor do limite superior. 2. Cada faixa de origem tem uma capacidade:
Para cada movimento de conversão de saída, o algoritmo subtrai a atratividade desejada desta capacidade, levando em conta o peso de uma faixa.
O resultado desse cálculo pode ser positivo ou negativo para uma faixa, o que significa que elas podem fornecer a capacidade desejada (usando a capacidade completa da faixa ou, às vezes, deixando capacidade excedente na faixa) ou têm um déficit (por exemplo, um destino deseja 1.000 PCUs, mas uma origem só pode fornecer 500 PCUs; isso criaria um déficit de 500).
Para cada faixa em s aplica-se o seguinte cálculo:
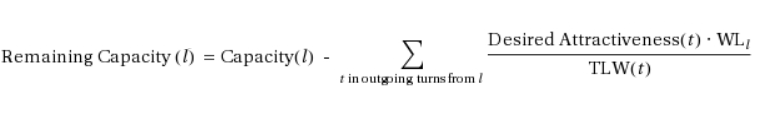
em que WLi = peso da faixa l
TLW = peso total das faixas de origem de um movimento de conversão
-
Após este cálculo, o algoritmo determina quais faixas ainda têm capacidade disponível e quais estão em déficit (incapazes de fornecer a capacidade desejada). Ele rotula essas faixas de origem a partir de s como A e B:
- Faixas Tipo A: este tipo de faixa tem uma capacidade restante maior ou igual a 0, o que é suficiente para fornecer a capacidade desejada a partir de seus movimentos de conversão e possivelmente ter alguma de sobra.
- Faixas Tipo B: este tipo de faixa não consegue fornecer a capacidade desejada. Ele pode precisar de 'ajuda' da capacidade remanescente de uma ou mais faixas do tipo A.
- Faixas do Tipo A redistribuem sua capacidade remanescente excedente entre as faixas do Tipo B com as quais compartilham movimentos de conversão.
-
Qualquer atratividade desejada que permaneça não atendida após esta redistribuição é corrigida. Isso é feito proporcionalmente entre as faixas de destino afetadas, usando o seguinte cálculo:
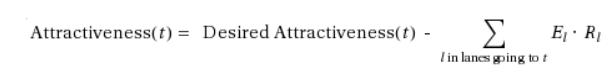
em que El = excesso de capacidade desejada atribuído por faixa
Rl = a razão entre a capacidade ainda necessária da faixa l para o movimento de conversão t e a capacidade total ainda necessária de l
As funções de custo de link devem sempre retornar um valor entre 0.000001 e 100000. Se a função de custo retornar um valor fora desse intervalo, o valor será substituído por um valor que garanta que os caminhos evitem usar esse link. O valor de substituição é a soma de todos os custos de link para uma determinada classe de usuário, multiplicada por 10. Um aviso é exibido na janela de log para todos os pares de movimento de conversão + classe de usuário que não retornarem um custo dentro do intervalo predefinido. - A REVISAR
Rede de Exemplo¶
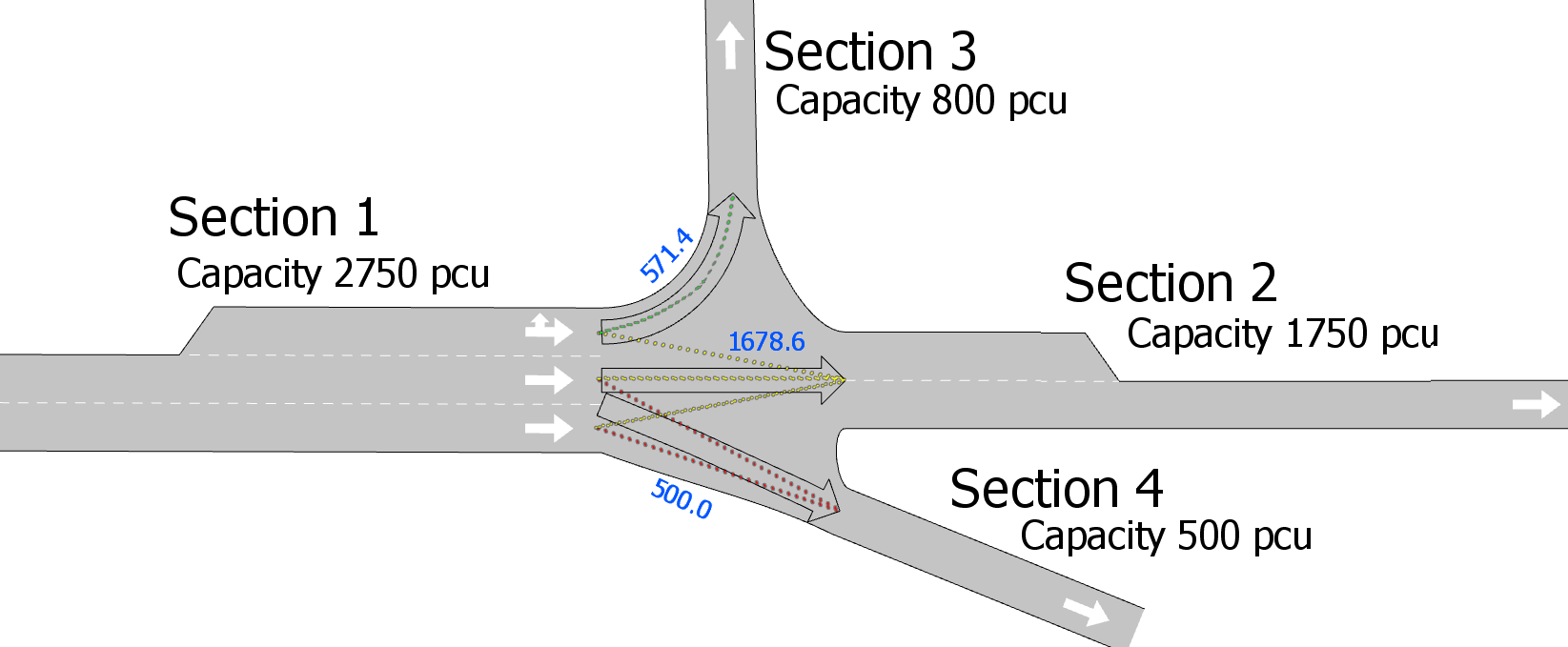
A ilustração abaixo mostra parte de uma rede do Aimsun. Ela compreende quatro seções (1, 2, 3 e 4) e uma interseção central que contém três movimentos de conversão. Isso corresponde a três links na rede equivalente de escolha de rota. A capacidade de cada seção é definida conforme indicado.
Os valores em azul indicam a capacidade real recebida por cada seção após a conclusão do algoritmo de cinco etapas explicado acima, levando em conta redistribuições de capacidade e correções.
As capacidades das faixas na Seção 1 de origem (faixas 1.1, 1.2 e 1.3) são as seguintes. Observe que a faixa 1.1 é uma faixa lateral com peso de 0,75.
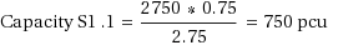
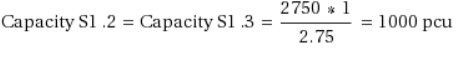
Neste exemplo, as cinco etapas do algoritmo prosseguem da seguinte forma.
-
A atratividade desejada por faixa é considerada:
- Link 1: S3 requer 800 PCUs de S1.1.
- Link 2: S2 requer 1.750 PCUs no total: 477,27 de S1.1 e 636,36 de ambos S1.2 e S1.3 por causa dos diferentes pesos das faixas.
- Link 3: S4 requer 500 PCUs no total: 250 de ambos S1.2 e S1.3.
-
A atratividade desejada é subtraída da capacidade das faixas. A capacidade restante nas faixas de origem é:
- Capacidade Restante S1.1 = 750 – 800 – 477.27 = -527.27
- Capacidade Restante S1.2 = 1,000 – 636.36 – 250 = 113.64
- Capacidade Restante S1.3 = 1,000 – 636.36 – 250 = 113.64
-
As faixas de origem são rotuladas como A ou B:
- Faixas S1.2 e S1.3 são faixas do tipo A, com capacidade remanescente que pode ser compartilhada com o movimento de conversão central S1.1 (uma faixa do tipo B).
-
A capacidade excedente é redistribuída para faixas com déficit:
- Capacidade de até 227,27 PCUs disponível em S1.2 + S1.3 que S1.1 ainda precisa será compartilhada com ele pelo movimento de conversão S2 obtendo mais capacidade de S1.2 e S1.3, deixando as seguintes capacidades:
- Capacidade Restante S1.1 = -527.27 + 227.27 = -300
- Capacidade Restante S1.2 = S1.3 = 0
- Capacidade de até 227,27 PCUs disponível em S1.2 + S1.3 que S1.1 ainda precisa será compartilhada com ele pelo movimento de conversão S2 obtendo mais capacidade de S1.2 e S1.3, deixando as seguintes capacidades:
-
Qualquer excesso de capacidade desejada é corrigido.
- Isto só é necessário para movimentos de conversão que tenham capacidade de faixa restante negativa na origem:
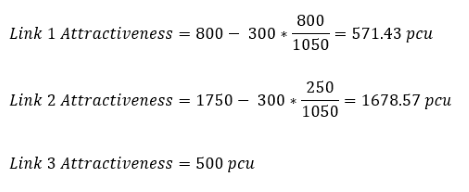
- Isto só é necessário para movimentos de conversão que tenham capacidade de faixa restante negativa na origem:
Custo Dinâmico¶
O padrão Custo em simulações dinâmicas, baseia-se principalmente no tempo de viagem. Quando há dados de tempo de viagem simulado disponíveis, isto é, veículos passaram pelo link depois que a simulação começou e os dados foram coletados, este será o tempo de viagem utilizado. No início da simulação, quando nenhum veículo ainda entrou em um link, o custo será calculado com base no tempo de viagem em fluxo livre. Por fim, quando veículos entraram em um link, mas nenhum veículo o atravessou completamente (input flow > 0, mas nenhum dado coletado), o tempo de viagem será estimado a partir dos veículos dentro do link.
O custo padrão, \(DynCost_{j,vt}\), pode diferenciar por tipo de veículo. É uma função do tempo médio de viagem, em segundos, para todos os veículos simulados de cada tipo de veículo que cruzaram o link durante o último período de coleta de estatísticas \(TravelTime_{j,vt}\), mais uma atratividade e um termo de custo fixo. O tempo de viagem para o link \(j\) inclui o tempo de viagem da seção s mais o tempo de viagem para o movimento de conversão \(t\).
O Custo Dinâmico do link \(j\) do tipo de veículo \(vt\): \(DynCost_{j,vt}\) é calculado como:
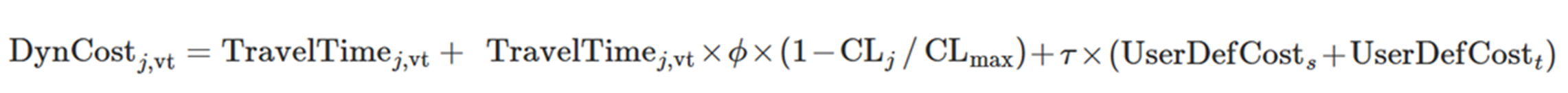
em que:
- \(TravelTime_{j,vt}\) é o tempo de viagem simulado do tipo de veículo \(vt\)do link \(j\) se disponível (estimado ou fluxo livre caso contrário).
- φ é um parâmetro de peso de atratividade definido pelo usuário que permite controlar a influência que a atratividade do link tem no custo em relação ao tempo de viagem.
- \(CL_{j}\) é a atratividade do link.
- \(CL_{max}\) é a atratividade máxima de link estimada teoricamente na rede.
- τ é um parâmetro de peso de custo definido pelo usuário que permite controlar a influência do custo definido pelo usuário no custo total.
- \(UserDefCost_{s}\) é o custo definido pelo usuário do link \(j\), que é a soma do custo definido pelo usuário da seção mais o custo definido pelo usuário do movimento de conversão.
Custo inicial em fluxo livre¶
O padrão custo inicial é usado no início da simulação, quando nenhum veículo entrou na rede e os dados simulados ainda não foram coletados e, portanto, nem os tempos de viagem estimados nem os experimentados estão disponíveis, até que os dados simulados estejam disponíveis. Nesse caso, o custo padrão de cada link é calculado em função do tempo de viagem em condições de fluxo livre, da atratividade do link e de um custo fixo. O tempo de viagem em condições de fluxo livre é o tempo que um veículo levaria para atravessar o link, que é a seção mais o movimento de conversão. Nenhuma penalidade de tempo é incluída para semáforos. Esse tempo de viagem, \(IniCost_{j,vt}\), que pode ser diferente por tipo de veículo, é calculado assumindo que o veículo está trafegando no mínimo entre a média do tipo de veículo Velocidade Desejada Máxima e o Limite de Velocidade da seção e do movimento de conversão multiplicado pela média do tipo de veículo Aceitação do Limite de Velocidade.
\(TravelTimeFreeFlow_{j,vt}\), o tempo de viagem estimado do tipo de veículo \(vt\) no link \(j\) em condições de fluxo livre, é calculado com a seguinte fórmula:
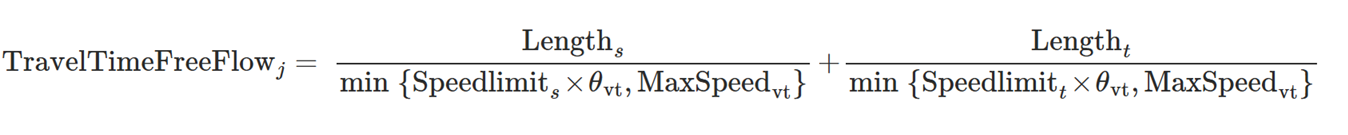
O limite de velocidade, a velocidade máxima média do tipo de veículo \(vt\), \(MaxSpeed_{vt}\) e a aceitação do limite de velocidade do tipo de veículo vt, θ\(_{vt}\), são usados para avaliar o tempo de viagem. O último parâmetro ( θ > 0) é o “nível de qualidade” dos motoristas ou o grau de aceitação dos limites de velocidade. Um valor de θ\(_{vt}\) ≥ 1 significa que o veículo pode trafegar a uma velocidade maior que o limite de velocidade da seção, enquanto θ\(_{vt}\) ≤ 1 significa que o veículo aplicará um limite de velocidade menor.
Custo dinâmico com tempos de viagem estimados ¶
Pode haver situações em que veículos já tenham entrado em um link, mas nenhum veículo que pertença ao tipo de veículo \(vt\) cruzaram um link, caso em que não há informações disponíveis sobre o tempo de viagem, então o seguinte algoritmo é aplicado para calcular \(EstimatedTravelTime_{j,vt}\):
if (Flow(j,vt) > 0) then
EstimatedTravelTime(j,vt) = TravelTime(j,vt)
else
if (there is any vehicle vt stopped) then
EstimatedTravelTime(j,vt) = AvgTimeIn(s,vt)
else
if (link j has reserved lanes of vehicle class cl) then
if (vt belongs to cl) then
if (FlowClass(j,cl) > 0) then
EstimatedTravelTime(j,vt) = TravelTimeClass(j,cl)
else
if (there is any vehicle belonging to cl stopped) then
EstimatedTravelTime(j,vt) = AvgTimeInClass(s,cl)
else
EstimatedTravelTime(j,vt) = AverageSectionTravelTime(s,cl)
endif
endif
else
if (FlowClass(j, not cl) > 0) then
EstimatedTravelTime(j,vt) = TravelTimeClass(j,not cl)
else
if (there is any vehicle not belonging to cl stopped) then
EstimatedTravelTime(j,vt) = AvgTimeInClass(s,not cl)
else
EstimatedTravelTime(j,vt) = AverageSectionTravelTime(s,not cl)
endif
endif
endif
else
if (Flow(v=j) > 0) then
EstimatedTravelTime(j) = TravelTime(j)
else
if (there is any vehicle stopped) then
EstimatedTravelTime(j) = AvgTimeInSection(s)
else
EstimatedTravelTime(j) = AverageSectionTravelTime(s)
endif
endif
endif
endif
endif
EstimatedTravelTime(j, vt) = Maximum(EstimatedTravelTime(j, vt), TravelFF(j, vt))
De acordo com este algoritmo, quando um veículo do tipo \(vt\) cruzou o link \(j\) durante o último período de coleta de dados (\(Flow_{j,vt}\) > 0), o custo atual é tomado como o tempo médio de viagem simulado. Se nenhum veículo do tipo \(vt\) cruzou o link \(j\), distinguimos entre diferentes casos de custos calculados de acordo com as etapas a seguir (cada etapa é executada se não houver informações disponíveis para a etapa anterior):
-
\(AvgTimeIn_{s,vt}\) : Tempo médio de espera do primeiro veículo do tipo de veículo vt na frente da fila na seção.
-
Se a seção s tem faixas reservadas para classe de veículo \(cl\):
- e tipo de veículo \(vt\) usa a faixa reservada:
- \(TravelTimeClass_{j,cl}\): É o Tempo Médio de Viagem do link \(j\) agregando todos os tipos de veículo da classe de veículo \(cl\).
- \(AvgTimeInClass_{s,cl}\): É o tempo médio de espera do primeiro veículo da classe de veículo \(cl\) à frente da fila na seção s.
- \(AverageSectionTravelTime_{s,cl}\): É o tempo médio de viagem na seção de todos os veículos da classe de veículo \(cl\).
- e tipo de veículo \(vt\) não usa as faixas reservadas:
- \(TravelTimeClass_{j,not\ cl}\): É o Tempo Médio de Viagem do link \(j\) agregando todos os tipos de veículos que não pertencem à classe de veículo \(cl\).
- \(AvgTimeInClass_{s,not\ cl}\): É o tempo médio de espera do primeiro veículo que não pertence à classe de veículo \(cl\) à frente da fila na seção s.
- \(AverageSectionTravelTime_{s,not\ cl}\): É o tempo médio de viagem na seção de todos os veículos que não pertencem à classe de veículo \(cl\).
- e tipo de veículo \(vt\) usa a faixa reservada:
-
Se a seção s não tem faixas reservadas:
- \(TravelTime_{j}\): É o Tempo Médio de Viagem do link \(j\) agregando todos
- tipos de veículos.
- \(AvgTimeIn_{s}\): É o tempo médio de espera do primeiro veículo à frente de
- a fila na seção s.
- \(AverageSectionTravelTime_{s}\): É o tempo médio de viagem na seção para todos os tipos.
Todos os tempos de viagem calculados devem ser maiores ou iguais ao tempo de viagem do link em condições de fluxo livre.
Funções de custo de link definidas pelo usuário¶
A função de custo padrão, descrita acima, é definida apenas em termos do tempo de viagem do link e considera explicitamente somente atratividade e custos fixos. Ela não inclui outras influências, por exemplo, tarifação complexa de pedágios, tempos de viagem históricos que representam a experiência dos motoristas de dias anteriores, combinações de vários atributos numéricos do link, como, por exemplo, tempos de viagem, tempos de atraso, comprimento e atratividade etc. Portanto, para cada link, pode ser usada uma função de custo definida pelo usuário que inclua quaisquer atributos. Ela é criada com o editor Cost Function, conforme descrito na Funções seção.
As funções de custo definidas pelo usuário podem usar as funções e operadores matemáticos mais comuns (+ , -, *, /, ln, log, exp etc.). Os termos da função podem ser definidos como parâmetros, constantes e variáveis, mas devem corresponder a atributos numéricos de um objeto no modelo (links, seções, movimentos de conversão, tipos de veículos etc.), cujos valores podem ser fixos (isto é, comprimentos, capacidades teóricas, número de faixas etc.) ou mudar durante a simulação (isto é, fluxos nos links, velocidades médias nos links, tempos médios de viagem nos links etc.).
As funções de custo podem distinguir entre tipos de veículo e, consequentemente, podem utilizar variáveis derivadas do tipo de veículo. Os parâmetros para este tipo de função são: S (a referência da seção do link), T (a referência de movimento de conversão do link) e o tipo de veículo VT referência.
Se a função de custo definida pelo usuário considerar dados de tipo de veículo associados a qualquer link da rede, o cálculo dos caminhos mínimos será feito por tipo de veículo; caso contrário, ele será comum a todos os tipos de veículo.
Caminhos de rota ¶
Algoritmo de Caminho Mais Curto ¶
Durante a simulação, os caminhos mais curtos são calculados em cada intervalo de tempo t (o Route Choice Interval). A rotina de caminho mínimo é uma variação do algoritmo de rotulação de Dijkstra, Dijkstra (1959), e fornece como resultado a árvore de caminhos mínimos para cada centroide de destino. Isso fornece o caminho mínimo a partir do início de cada seção até esse centroide de destino. Como isso inclui as penalidades de conversão, os rótulos de custo são associados aos links em vez dos nós da rede.
A rotina de caminho mais curto é baseada em funções de custo de links. Portanto, os custos de todos os links são avaliados/atualizados antes que os caminhos sejam calculados. No início da simulação, a função de custo é avaliada para cada link (considerando os custos iniciais de fluxo livre) e, durante os próximos intervalos de tempo, o custo dinâmico é usado.
A rotina de caminho mais curto gera uma árvore de caminhos mais curtos para cada centroide de destino d(\(SPT_{d}\),d ∈ D), mas há uma etapa extra que identifica novos caminhos para todos os pares OD i ∈ I, considerando \(SPT_{d}\),d ∈ D*, e adiciona ao conjunto de caminhos alternativos \(K_{i}\) do par OD \(i\). A partir de uma árvore de caminhos mínimos, há tantos caminhos \(SP_{con}\) como conexões \(con\) para o centroide de origem.
O esquema genérico da Atribuição Dinâmica de Tráfego é:
Etapa 0: Calcule o(s) caminho(s) mínimo(s) inicial(is) para cada par OD usando os custos definidos (iniciais).
Etapa 1: Simular por um intervalo de tempo predefinido (por exemplo, 5 minutos), alocando ao caminho disponível a fração das viagens entre cada par OD para esse intervalo de tempo de acordo com o modelo de escolha de rota selecionado, e obter novos tempos médios de viagem nos links como resultado da simulação.
Etapa 2: Recalcular o caminho mais curto, levando em conta os tempos médios de viagem experimentados nos links.
Etapa 3: Se houver veículos guiados, ou painéis de mensagens variáveis sugerindo uma mudança de rota, forneça as informações calculadas em 2 aos motoristas que estão dinamicamente autorizados a atualizar o caminho em rota.
Etapa 4: Vá para a etapa 1.
E o algoritmo, incluindo os detalhes do cálculo do caminho mínimo, é o seguinte:
Etapa 0: Calcular o(s) caminho(s) mais curto(s) inicial(is) para cada par OD usando os custos iniciais
- Step 0.1:Inicialização:
- Avaliar a Função de Custo Dinâmico com condições Iniciais de Fluxo Livre para cada link \(j\):
- para cada \(j\) ∈ (1... \(L\)) :
- \(Cost_{j}\) = \(InitialCost_{j}\)
- Step 0.2: Aplicar rotina de Caminho Mais Curto:
- para cada centroide de destino \(d\):
- Calcular a Árvore de Caminhos Mais Curtos \(SPT_{d}\) usando \(Cost_{j}\) \(j\) ∈ (1... \(L\))
- para cada centroide de destino \(d\):
- Step 0.3: Identificar o Caminho Mais Curto a partir da Árvore de Caminhos Mais Curtos:
- para cada par OD \(i\) (do centroide de origem \(o\) ao destino \(d\))
- Adicionar ao(s) caminho(s) \(SP_{con}\) para \(K_{i}\)
- para cada par OD \(i\) (do centroide de origem \(o\) ao destino \(d\))
Etapa 1: Simular por um intervalo de tempo predefinido Δ\(t\) atribuindo ao caminho disponível \(K_{i}\) a fração das viagens entre cada par OD \(i\) para esse intervalo de tempo de acordo com o modelo de escolha de rota selecionado.
Etapa 2: Recalcular o caminho mais curto, avaliando o custo dinâmico levando em conta os tempos médios de viagem dos links a partir da simulação.
- Step 2.1: Atualizar Funções de Custo de Link:
- Avaliar a Função de Custo Dinâmico para cada link \(j\):
- para cada \(j\) ∈ (1... \(L\)) : \(Cost_{j}\) = \(DynamicCost_{j}\)
- Step 2.2: Aplicar rotina de Caminho Mais Curto:
- para cada centroide de destino \(d\):
- Calcular a Árvore de Caminhos Mais Curtos \(SPT_{d}\) usando \(Cost_{j}\) \(j\) ∈ (1... \(L\))
- Step 2.3: Identificar o Caminho Mais Curto a partir da Árvore de Caminhos Mais Curtos:
- para cada par O-D \(i\) (da origem \(o\) ao destino \(d\))
- Adicionar ao(s) caminho(s) \(SP_{con}\) para \(K_{i}\)
- para cada par O-D \(i\) (da origem \(o\) ao destino \(d\))
Etapa 3: Se houver veículos guiados, ou painéis de mensagens variáveis sugerindo uma mudança de rota, forneça as informações calculadas em 2 aos motoristas que estão dinamicamente autorizados a atualizar o caminho em rota.
Etapa 4: Vá para a etapa 1.
Este cálculo de caminho mínimo é feito para cada tipo de veículo, mas em algumas situações os tipos de veículo são agrupados para melhorar o desempenho do cálculo de caminhos. Os tipos de veículo são agrupados quando as funções de custo do link são as padrão - se forem usadas funções de custo definidas pelo usuário, os tipos de veículo nunca serão agrupados. Além disso, dois tipos de veículo não podem ser agrupados quando: - há qualquer seção em que a velocidade máxima permitida é diferente por tipo de veículo. - há qualquer seção em que um dos tipos de veículo pode entrar e o outro não é permitido. Um tipo de veículo pode não ter permissão para entrar em uma seção devido a faixas reservadas ou tipos de veículo proibidos. - o número máximo de caminhos é diferente para esses dois tipos de veículo.
K-Caminhos Mais Curtos Iniciais¶
No início da simulação, usando a função de custo dinâmica com custos iniciais em condições de fluxo livre, uma árvore de caminhos mínimos é calculada para cada centroide de destino; portanto, todos os veículos são atribuídos à mesma alternativa durante o primeiro intervalo. Para considerar mais de uma alternativa, como forma de antecipar o processo de atribuição, \(k\) árvores de caminhos mais curtos pode ser calculado no início da simulação usando o K caminhos mais curtos iniciais função.
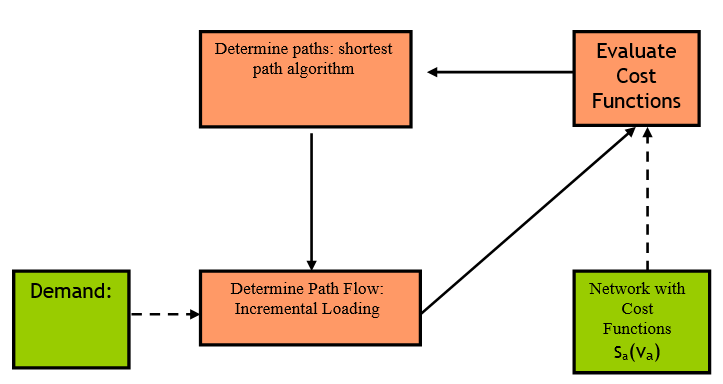
O algoritmo executa um alocação estática incremental, calculando a cada iteração um novo caminho mais curto até que o número de árvores de caminhos mais curtos disponíveis alcance o parâmetro K-Caminhos Mais Curtos Iniciais e carregando a cada iteração o 100/K % da demanda. A figura acima mostra o esquema genérico do algoritmo que, iterativamente:
- Avalia a função de custo em cada link. Na primeira iteração, a função de custo é a função de custo dinâmica com condições iniciais (tempo de viagem em condições de fluxo livre por padrão) e, nas iterações seguintes, a função de custo é a função de custo dos caminhos mais curtos K-iniciais.
- Calcula um novo caminho mais curto.
- Determina o fluxo do caminho usando um procedimento de carregamento incremental, descrito abaixo, e atualiza o fluxo em cada link.
Os componentes deste algoritmo são:
-
O Shortest Path Algorithm que calcula o caminho mais curto e corresponde a uma variação do algoritmo de definição de rótulos de Dijkstra.
-
O link Função de Custo K-Initials, \(s_{a}\)(\(v_{a}\)), que é função do fluxo no link \(a\), \(v_{a}\).
-
O Algoritmo de Carregamento Incremental que atribui a demanda. As taxas de fluxo de caminhos na região viável satisfazem a conservação de fluxo e a restrição de não negatividade (onde a demanda de tráfego do par OD \(i\) é denotado por \(g_{i}\) e o fluxo de caminho atribuído ao caminho k do par OD i é denotado por \(h_{k}\)^i^). That is:
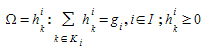
Para cada par OD \(i\) ∈ \(I\) e caminho \(h_{k}\)^i^, avalia o fluxo de caminho alocado ao caminho \(h_{k}\)^i^ \(k\) ∈ \(K_{i}\) na iteração \(n\):
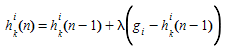
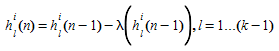
em que
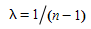
K caminhos mais curtos ¶
O algoritmo para calcular o \(k\)-caminho mais curto pode ser formulado da seguinte forma (\(n\) é o índice de iteração e \(k\) é o índice do caminho mais curto):
Etapa 0: Inicialização: \(n\)=0 e \(k\)=1
- Calcular o primeiro caminho mais curto com base nos tempos de viagem em fluxo livre (usando a função Dynamic Cost em condições de fluxo livre)
- Para cada par O-D \(i\) ∈ \(I\),
- atribuir \(h_{k}\)^i^(n)=\(g_{i}\) / InitialK-SP*
Etapa 1: Calcular o fluxo \(v_{a}\) para cada link \(a\):
-
Avaliar a função de custo de cada arco \(a\) (\(s_{a}\)(\(v_{a}\))).
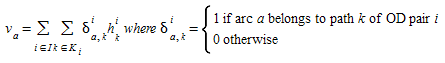
Etapa 2: \(k\)= \(k\) +1, \(n\) = \(n\) +1.
-
Calcular o k-ésimo caminho mais curto com base na função de custo K-initials para cada arco \(a\) (\(s_{a}\)(\(v_{a}\))).
Carregamento Incremental: Para cada par O-D \(i\) ∈ \(I\), avalie:
em que
Etapa 3: Se \(k\) é igual ao número total de caminhos mais curtos InitialK-SP
- então STOP
- Caso contrário, retorne à Etapa 1
Função de Custo de Caminho Mínimo K-Initials¶
Quando K > 1, o Função de custo de caminho mínimo K-initials é usado no início da simulação, quando ainda não foram coletados dados simulados para calcular os k caminhos mais curtos iniciais que representam uma função volume-atraso. Nesse caso, o custo de cada link é calculado como uma função do volume alocado. O \(IniKCost_{j,vt}\) pode distinguir por tipo de veículo.
O usuário pode definir uma função de custo de caminhos mínimos K-initials própria; caso contrário, será usada a padrão. O custo K-initials padrão do link \(j\), \(IniKCost_{j}\) é calculado da seguinte forma:
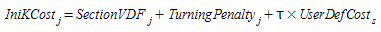
em que
-
\(SectionVDF_{j}\) é o atraso estimado da seção \(s\) no link \(j\) em segundos considerando o fluxo atribuído:
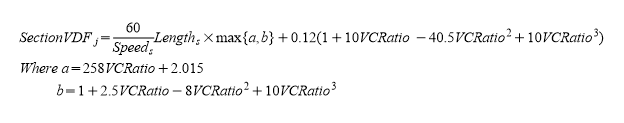
em que \(Length_{s}\) é o comprimento, \(Speed_{s}\) é a velocidade da seção \(s\), que pertence ao link \(j\), em km e \(VCRatio\) é o volume alocado do link \(j\) dividido pela atratividade do link \(j\).
-
\(TurningPenalty_{j}\) é a penalidade do movimento de conversão \(t\) no link \(j\) em segundos considerando a velocidade do movimento de conversão da seguinte forma:

TurningLength é o comprimento do movimento de conversão em km.
-
\(τ\) é um parâmetro de peso de custo definido pelo usuário que permite controlar a influência do custo definido pelo usuário sobre o custo.
- \(UserDefCost_{s}\) é o custo definido pelo usuário da seção \(s\), que pertence ao link \(j\).
O custo padrão K-initials do link \(j\) por tipo de veículo \(vt\), \(IniKCost_{j,vt}\), é calculado como o custo K-initials sem considerar o tipo de veículo, exceto no caso em que o movimento de conversão não é permitido para \(vt\) que o custo será infinito para impedir que os veículos passem por ele.
Seleção de caminho¶
A seleção de caminhos, que se baseia em modelos discretos de escolha de rota ou em uma alocação definida pelo usuário, é usada para estimar as taxas de fluxo nos caminhos. A seleção de caminhos modela a decisão do motorista sobre qual caminho seguir a partir de um conjunto de alternativas que conectam uma origem a um destino. Esse processo de decisão é realizado quando um veículo entra no sistema (Alocação Inicial) e também durante sua viagem, quando novas alternativas estão disponíveis (Atualização da Alocação de Caminho em Rota).
Dado um conjunto finito de caminhos alternativos, a seleção de caminhos calcula a probabilidade de usar cada caminho disponível e então a decisão do motorista é modelada selecionando aleatoriamente um caminho de acordo com as probabilidades atribuídas a cada alternativa. Esse processo corresponde à Etapa 1 no algoritmo genérico de Atribuição Dinâmica e, em combinação, leva ao seguinte algoritmo:
Etapa 0: Calcular caminho(s) mínimo(s) inicial(is) para cada par OD usando os custos iniciais definidos
-
Step 0.1: Inicialização: Avaliar a Função de Custo para cada link \(j\):
- para cada \(j\) ∈ 1... \(L\) \(Cost{j}\) = \(InitialCost_{j}\)
-
Step 0.2: Aplicar rotina de Caminho Mais Curto:
- para cada centroide de destino \(d\): Calcular Árvore de Caminhos Mais Curtos \(SPT_{d}\) usando \(Cost_{j}\) \(j*\) ∈ 1... \(L\)
-
Step 0.3: Identificar o Caminho Mais Curto a partir da Árvore de Caminhos Mais Curtos:
- para cada par OD \(i\) (do centroide de origem \(o\) ao destino \(d\))
- Adicionar ao(s) caminho(s) \(SP_{con}\) para \(K_{i}\)
Etapa 1: Simular por um intervalo de tempo predefinido Δ\(t\) atribuindo ao caminho disponível \(K_{i}\) a fração das viagens entre cada par OD \(i\) para esse intervalo de tempo de acordo com o modelo de escolha de rota selecionado.
- Step 1.1: Atribuição de probabilidades de caminho:
- para cada par O-D \(i\):
- Calcular \(P_{k}\) usando o Modelo de Escolha de Rotas,onde \(k\) ∈ \(K_{i}\)
- Step 1.2: Simular por um intervalo de tempo predefinido Δ\(t\), gerando a fração dos veículos entre cada par OD \(i\) para esse intervalo de tempo, selecionando aleatoriamente o caminho de acordo com as probabilidades \(P_{k}\) ,\(k\) ∈ \(K_{i}\)
Etapa 2: Recalcula o caminho mais curto, levando em conta os tempos médios de viagem nos links do experimento.
- Step 2.1: Atualizar Funções de Custo de Link:
- Avaliar a Função de Custo Dinâmico para cada link \(j\):
- para cada \(j\) ∈ 1... \(L\)
- \(Cost_{j}\) = \(DynamicCost_{j}\)
- Step 2.2: Aplicar rotina de Caminho Mais Curto:
- para cada centroide de destino \(d\):
- Calcular a Árvore de Caminhos Mais Curtos \(SPT_{d}\) usando \(Cost_{j}\) \(j\) ∈ 1... \(L\)
- para cada centroide de destino \(d\):
- Step 2.3: Identificar o Caminho Mais Curto a partir da Árvore de Caminhos Mais Curtos:
- para cada par OD \(i\) (do centroide de origem \(o\) ao destino \(d\))
- Adicionar ao(s) caminho(s) \(SP_{con}\) para \(K_{i}\)
- para cada par OD \(i\) (do centroide de origem \(o\) ao destino \(d\))
Etapa 3: Se houver veículos que aceitam atualizar sua rota em percurso, ou painéis de mensagens variáveis que sugerem atualizações de rota por meio de ações de gerenciamento de tráfego; forneça aos motoristas que têm permissão dinâmica para atualizar a rota em percurso as informações calculadas na etapa 2.
Etapa 4: Vá para a etapa 1.
Os caminhos candidatos podem ser de três tipos diferentes (explicados na Definição de Caminho seção): OD Routes (ODR), Path Assignment Result (PAR) e Calculated Shortest Paths, que podem ser calculados usando a Initial Cost Function Caminhos Mais Curtos Iniciais (ISP) ou calculado usando a Dynamic Cost Function, Caminhos Mínimos Dinâmicos (DSP).
Um veículo do tipo de veículo \(vt\) viajando do par OD \(i\), pode escolher um caminho de acordo com a atribuição definida pelo usuário ou como resultado de um modelo de Escolha de Rota a partir do conjunto de caminhos alternativos \(K_{i}\):
- \(N\) Rotas OD: \(ODR_{n}\)^i^ \(n\)=1..\(N\)
- \(M\) Caminho a partir dos resultados de Atribuição: \(PAR_{m}\)^i^ \(m\)=1..\(M\)
- \(P\) Caminhos mínimos iniciais: \(ISP_{p}\)^i^ , \(p\)=1..\(M\)
- \(Q\) Caminhos Mais Curtos Atualizados em Tempo Hábil: \(DSP_{q}\)^i^, \(q\)=1..\(Q\)
Seleção definida pelo usuário ¶
A seleção definida pelo usuário determina a probabilidade de uso para rotas OD e para o resultado de atribuição de caminhos.
Para cada rota OD, o usuário determina a probabilidade de uso, distinguindo por tipo de veículo (definido "Atribuição de caminhos" pasta na definição da matriz OD). O usuário define a probabilidade de uso de cada rota OD e a probabilidade de uso do caminho inicial mais curto:
\(P\)(\(ODR_{n}\)^i^, \(vt\)) : Probabilidade de uso \(ODR_{n}\)^i^ por um tipo de veículo \(vt\)
\(P\)(\(ISP_{p}\)^i^, \(vt\)) : Probabilidade de uso \(ISP_{p}\)^i^ por um tipo de veículo \(vt\)
Satisfazendo a condição:
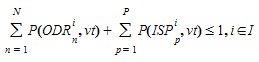
Ao aplicar uma atribuição estática de tráfego ou uma atribuição dinâmica de tráfego baseada em um experimento de Dynamic User Equilibrium, o resultado é um resultado de Path Assignment, que é um conjunto de caminhos (\(PAR_{m}\)^i^) e uma porcentagem de uso para cada um:
\(P\)(\(PAR_{m}\)^i^, \(vt\)) : Probabilidade de uso \(PAR_{m}\)^i^ por um tipo de veículo \(vt\)
Satisfazendo a condição:
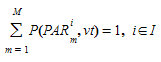
Modelos de Escolha de Rota¶
A qualquer momento durante a simulação, haverá um conjunto finito de trajetórias alternativas para cada par OD. A emulação da decisão do motorista de selecionar uma das trajetórias disponíveis, isto é, atribuir uma viagem a uma trajetória, é feita com um modelo de Route Choice. Os modelos de Route Choice são normalmente baseados na teoria de escolha discreta, que determina a probabilidade de escolher uma alternativa de um conjunto finito de alternativas em função de sua utilidade. Do ponto de vista dos transportes, o valor mais comum associado a uma viagem é o tempo de viagem ou o custo de viagem, que representa uma desutilidade. Portanto, os modelos de Route Choice devem ser formulados em termos dessa utilidade negativa. O conceito mais comum de custo de trajetória assume que ele é aditivo, de modo que o custo da trajetória \(I\), \(CP_{i}\), é calculado como a soma dos custos dos links \(Cost_{j}\) (explicado acima) que compõem o caminho:
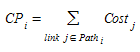
Os modelos padrão de Escolha de Rota disponíveis são: Proporcional, Logit Multinomial e C-Logit, mas outros também podem ser definidos usando o editor de funções.
Modo de Rotas Fixas Vs. Modo de Rotas Variáveis¶
No Fixed Routes Mode, árvores de caminho mais curto são calculadas de cada seção para cada centroide de destino no início da simulação. Em seguida, durante a simulação, os veículos são gerados nos centroides de origem e atribuídos à rota mais curta até seu centroide de destino. Não há necessidade de um Route Choice Model, pois não há rotas alternativas. Nenhuma nova rota é recalculada durante a simulação. Portanto, todos os veículos sempre seguem o caminho mais curto e nenhuma decisão de mudar para outro caminho pode ser tomada durante a viagem.
Dependendo do tipo de função de custo usada para os cálculos iniciais de caminho mínimo, existem dois modelos alternativos de rota fixa. Estes são o Fixo usando Tempo de Viagem em Condições de Fluxo Livre (anteriormente identificado como Distância Fixa) e o Fixo usando Tempo de Viagem durante o Período de Aquecimento (anteriormente identificado como Tempo fixo) modelos.
No Fixo usando Tempo de Viagem em Condições de Fluxo Livre Modelo, os caminhos são calculados no início de uma simulação, tomando o custo inicial como o custo de cada arco, independentemente de um período de aquecimento estar definido ou não. Se houver um período de aquecimento, nenhum novo caminho mais curto será calculado quando ele terminar e, portanto, as mesmas árvores de caminhos mais curtos serão usadas durante o período estacionário da simulação. A próxima figura ilustra quando os caminhos mais curtos (SP) são calculados em um diagrama temporal do período de simulação.
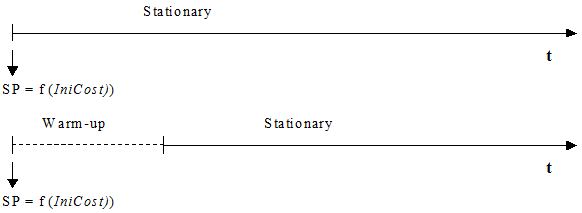
O Fixo usando Tempo de Viagem durante o Período de Aquecimento Modelo funciona de forma semelhante ao Fixo usando Tempo de Viagem em Condições de Fluxo Livre Modelo, exceto quando um período de Warm-up é definido. Nesse caso, os caminhos iniciais são calculados no início do Warm-up da mesma forma, usando os Initial Costs. No entanto, quando o período de Warm-up termina e a simulação estacionária começa, novos caminhos iniciais são calculados usando a Cost Function (calculada usando os dados estatísticos coletados durante o aquecimento da simulação) para os custos dos links. A próxima figura ilustra os cálculos dos caminhos mínimos (SP) em um diagrama de tempo do período de simulação.
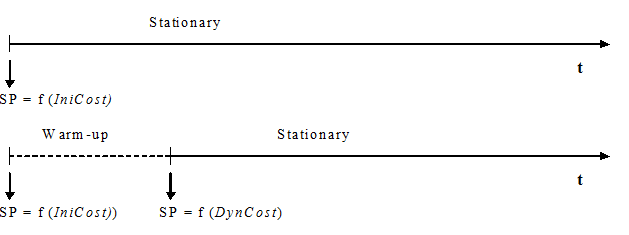
No Fixo usando Tempo de Viagem em Condições de Fluxo Livre Modelo, o custo não leva em conta o congestionamento da rede, apenas o comprimento dos caminhos e a velocidade permitida. Ele é rotulado Fixo usando Tempo de Viagem em Condições de Fluxo Livre Modelo para indicar que o custo é baseado principalmente nas distâncias, juntamente com os limites de velocidade e a atratividade, mas não nas condições de tráfego em um determinado momento. No Fixo usando Tempo de Viagem durante o Período de Aquecimento Modelo o custo é influenciado pelas condições de tráfego e, portanto, representa o tempo de viagem com mais precisão.
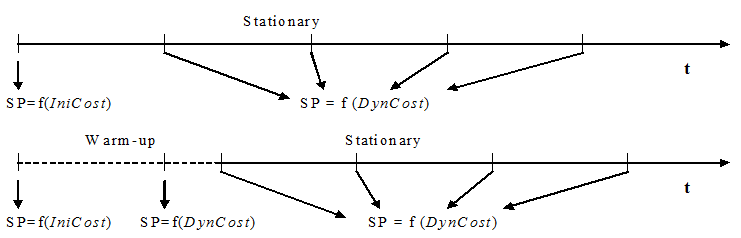
No modo de rotas variáveis, o processo de simulação inclui: um cálculo inicial das rotas mais curtas indo de cada seção para cada destino, um componente de rota mais curta que calcula periodicamente as novas rotas mais curtas de acordo com os novos tempos de viagem fornecidos pelo simulador, e um modelo de seleção de rotas.
No início da simulação, árvores de caminho mínimo são calculadas a partir de cada seção para cada centroide de destino, tomando como custos dos links a função de custo inicial, como no caso anterior. Se um período de Warm-up estiver definido, esses caminhos são calculados no início do Warm-up. Caso contrário, são calculados no início do período de simulação estacionária.
Durante a simulação, novos caminhos são recalculados em cada intervalo de tempo, usando como custos dos links os tempos de viagem simulados obtidos para cada arco durante o último intervalo. Esta é a função de custo explicada acima. A próxima figura ilustra quando os caminhos mais curtos (SP) são calculados ao longo do período de simulação e quais funções de custo são usadas.
O intervalo de tempo para recálculo dos caminhos é definido no Editor de experimento. Assume-se que os veículos escolhem apenas entre as melhores K árvores de caminho. Esses K caminhos são os pats calculados nos intervalos anteriores mais as OD Routes definidas nas matrizes OD. Apenas n As Rotas OD serão adicionadas ao conjunto de caminhos possíveis. Isto n parâmetro é definido no Editor de experimento.
Atualmente, quatro modelos de escolha estão implementados. Eles são usados ao atribuir o caminho inicial a um veículo no início de sua viagem ou quando é necessário decidir se ele deve mudar de caminho em rota dentro da modelagem dinâmica. Esses modelos são os modelos Binomial, Proportional, Multinomial Logit e C-Logit. Outros Route Choice Models podem ser definidos usando o Editor de Função de Custo.
Atribuição dinâmica¶
Quando uma matriz OD foi carregada em um modelo Aimsun, o experimento de simulação deve ser baseado em rotas. Antes de executar o modelo, qual tipo de Modelo de Escolha de Rotas usar e seus parâmetros é definido no Aba DTA do editor de experimento.
Há quatro modelos de escolha de rota que exigem parâmetros para controlar o comportamento da rota para cada par OD; estes são:
- Binomial: probabilidade.
- Proporcional: fator alpha.
- Logit: fator de escala.
- C-logit: fator de escala, beta e gamma.
Os parâmetros são definidos no subaba Parâmetros da aba Dynamic Traffic Assignment no Editor de Experimento
Modelo binomial¶
Uma Binomial (\(k\)-1, \(p\)) é usada para encontrar a probabilidade de selecionar cada caminho. O parâmetro k é o número de caminhos disponíveis e p é a probabilidade de "success". Este modelo não considera os custos de viagem no processo de decisão, mas apenas o momento em que o caminho foi calculado. Selecionar um p pequeno significará que os caminhos mais antigos terão maior probabilidade de ser usados, enquanto selecionar valores altos de p fará com que os caminhos mais recentes sejam tomados com mais frequência.
Por exemplo, se o objetivo é manter três caminhos alternativos e fazer com que os caminhos mais novos sejam usados com mais frequência, então defina \(k\)=3 e \(p\)=0.9. Então os valores possíveis para \(X\) = Binomial (2, 0.9) são \(X\) = 0,1,2 que estão respectivamente associados às últimas três trajetórias calculadas. Suponha que o intervalo de tempo para recalcular os caminhos mais curtos seja de 5 minutos e que o tempo atual da simulação seja 25:30. Nesse caso, as últimas três trajetórias calculadas foram calculadas nos tempos 15:00, 20:00 e 25:00, portanto, correspondentemente \(X\) = 0 to 15:00, \(X\) = 1 to 20:00 and \(X\) = 2 a 25:00. Então, a probabilidade de selecionar o caminho mais antigo é \(P\)(\(X\)=0) = 0.01, a probabilidade de selecionar o segundo caminho é \(P\)(\(X\)=1) = 0.18 e a probabilidade de selecionar o caminho mais novo é \(P\)(\(X\)=2) = 0.81 (A próxima figura ilustra o modelo binomial com \(k\)=3 e \(p\)=0.9).
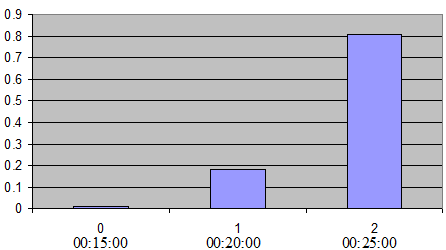
A probabilidade de ‘success’ \(p\) pode ser definido por meio de Aba de parâmetros de Escolha de Rota do Editor de Experimento quando o modelo Binomial é escolhido.
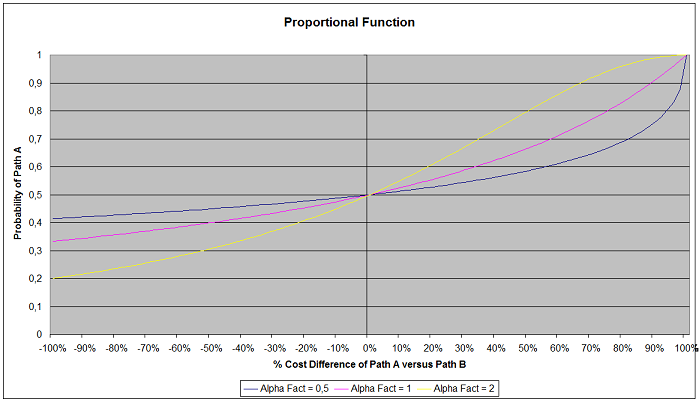
Proporcional¶
A probabilidade de escolha \(P_{k}\) de um caminho alternativo determinado \(k\) , onde \(k\) ∈ \(K_{i}\), pode ser expresso como:
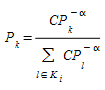
em que \(CP_{i}\) é o custo do caminho \(i\).
Quando α =1, então a probabilidade é inversamente proporcional aos custos dos caminhos. A próxima figura mostra o papel do fator alfa, em função dos diferentes custos dos caminhos. Consequentemente, o fator alfa pode ser usado para ajustar o efeito que pequenas alterações nos tempos de viagem podem ter nas decisões dos motoristas.
Logit Multinomial¶
A probabilidade de escolha \(P_{k}\) de um caminho alternativo determinado \(k\), onde \(k\) ∈ \(K_{i}\), pode ser expressa como uma função da diferença entre as utilidades medidas desse caminho e todos os outros caminhos alternativos:
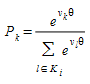
ou sua expressão equivalente:
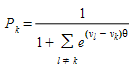
em que \(V_{i}\) é a utilidade percebida para a trajetória alternativa \(i\) e θ é um fator de forma ou escala e \(V_{i}\) = -\(CP_{i}\)/3600 (function \(V_{i}\) é o negativo do custo do caminho \(i\), medido em horas).
Assumimos que a utilidade do caminho k entre o par OD \(i\) é dado por:
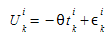
Onde:
- θ é um parâmetro de fator de forma ou escala
- \(t_{k}\)^i^ é o tempo de viagem esperado no caminho \(k\) do par OD \(i\)
- ε\(_{k}\)^i^ é um termo aleatório
A hipótese de modelagem subjacente é que os termos aleatórios ε\(_{k}\)^i^ são independentes e identicamente distribuídos variáveis GUMBEL. Nessas condições, a probabilidade de escolher o caminho \(k\) entre todas as rotas alternativas do par OD \(i\) é dada pela distribuição logística:
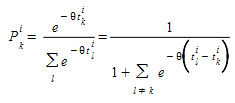
O fator de escala θ desempenha um papel duplo, tomando a decisão com base em diferenças entre utilidades independentes das unidades de medida e influenciando o erro padrão da distribuição dos tempos de viagem esperados:
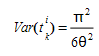
onde se:
- θ < 1 alta percepção da variância, em outras palavras, uma tendência a utilizar muitas rotas alternativas.
- θ > 1 escolhas alternativas ficam concentradas em pouquíssas rotas.
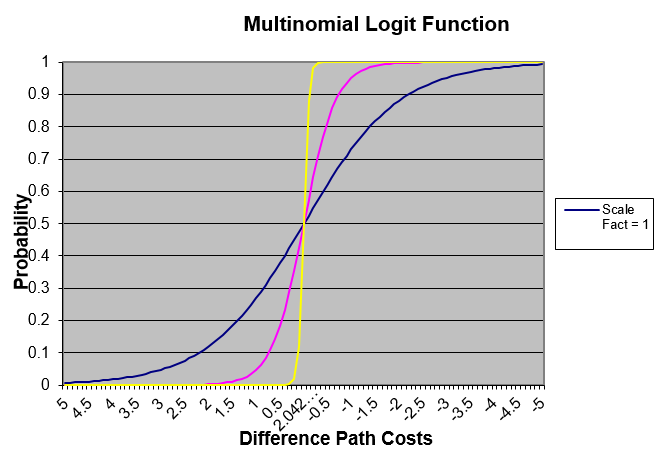
Por exemplo, considerando quatro caminhos alternativos com tempo de viagem esperado (custo do caminho) de \(T_{1}\)=12 minutos, \(T_{2}\)=15 minutos, \(T_{3}\)=16 minutos e \(T_{4}\)=18 minutos, as probabilidades correspondentes quando θ = 1 são: \(P_{1}\)=0.93407, \(P_{2}\)=0.04650, \(P_{3}\)=0.01710 and \(P_{4}\)=0.00231, enquanto se θ = 0.5 as probabilidades são: \(P_{1}\)=0.71009, \(P_{2}\)=0.15844, \(P_{3}\)=0.09610 and \(P_{4}\)=0.03535.
A próxima figura ilustra o papel do fator de escala, em função da diferença entre os custos dos caminhos:
C Logit¶
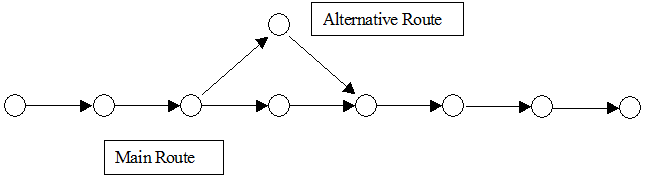
Os modelos Logit exibem uma tendência a oscilações de rota nas rotas usadas, com a instabilidade correspondente resultando em um processo de alternância. De acordo com nossa experiência, há duas razões principais para esse comportamento. As propriedades da função Logit e a incapacidade da função Logit de distinguir entre duas rotas alternativas quando há um alto grau de sobreposição. Alguns pesquisadores Cascetta (2001) relataram essas desvantagens.
A instabilidade das rotas utilizadas pode ser substancialmente melhorada quando a topologia da rede permite caminhos alternativos com pouca ou nenhuma sobreposição, alterando o fator de forma e recalculando o caminho com muita frequência. No entanto, em redes grandes, onde existem muitos caminhos alternativos entre origens e destinos e alguns deles apresentam certo grau de sobreposição (veja a próxima figura), o uso da função Logit ainda pode apresentar algumas fragilidades.
Para evitar esta desvantagem, o modelo C-Logit, (Cascetta 2001), foi implementado. No modelo C-Logit, que é, de fato, uma variação do modelo Logit, a probabilidade de escolha \(P_{k}\), de cada caminho alternativo \(kEK_{i}\) de caminhos disponíveis conectando um par OD, é expresso como:
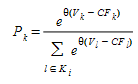
em que \(V_{i}\) é a utilidade percebida para a trajetória alternativa \(i\) (expresso em horas) e θ é o fator de escala, como no caso do modelo Logit.
O termo \(CF_{k}\), denotado como ‘fator de comunalidade’ do caminho k, é diretamente proporcional ao grau de sobreposição do caminho k com outros caminhos alternativos. Assim, caminhos altamente sobrepostos têm um fator CF maior e, portanto, utilidade menor em relação a caminhos semelhantes. \(CF_{k}\) é calculado da seguinte forma:
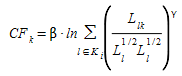
em que \(L_{lk}\) é o custo dos links comuns aos caminhos l e k, enquanto \(L_{l}\) e \(L_{k}\) são o custo dos caminhos \(l\) e \(k\) respectivamente (expressos em horas). Dependendo dos dois parâmetros de fator β e γ, é atribuído um peso maior ou menor ao ‘commonality factor’. Valores maiores de β significam que o fator de sobreposição tem maior importância em relação à utilidade \(V_{i}\). O fator γ é um parâmetro positivo, geralmente considerado no intervalo [0, 2], cuja influência é menor que β e que tem efeito oposto sobre a escolha.
Como regra prática, sugere-se que o fator β esteja no intervalo [\(t_{min}\), \(t_{max}\)], com \(t_{min}\) = \(Min_{kEKi}\) [\(CP_{k}\)] e \(t_{max}\) = \(Max_{kEKi}\) [\(CP_{k}\)]. Então β se tornará um fator de escala para \(CP_{k}\), o que o traduz em uma ordem de magnitude semelhante a \(V_{k}\) na fórmula \(V_{k}\) - \(C_{k}\) usado para a exponencial. Assim, ao usar valores maiores para β, é possível que o ‘commonality factor’, \(CF_{k}\), terá uma influência maior sobre a probabilidade de escolha do que a própria utilidade (isto é, o tempo de viagem), dando assim maior probabilidade de escolher caminhos mais longos não sobrepostos do que caminhos mais curtos com alta sobreposição. Observe que o fator de comunalidade não é aplicado à melhor alternativa.
A seguir há um exemplo para ilustrar o uso do C-Logit, comparando-o com o Logit Multinomial. A figura mostra uma rede de exemplo com quatro caminhos alternativos entre a origem O e o destino D. A tabela representa as probabilidades de escolha resultantes de ambos os modelos.
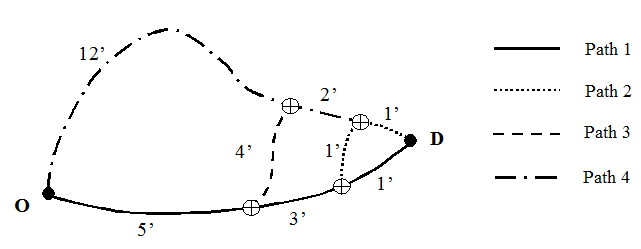
| Tempos de viagem | Caminho 1 | Caminho 2 | Caminho 3 | Caminho 4 |
|---|---|---|---|---|
| segundos | 540 | 600 | 720 | 900 |
| minutos | 9 | 10 | 12 | 15 |
| horas | 0.15 | 0.16 | 0.2 | 0.25 |
Sobreposição \((l*lk)* v\)
| l / k | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 1 | 0.1500 | 0.1333 | 0.0833 | 0.0000 |
| 2 | 0.1333 | 0.1667 | 0.1000 | 0.0167 |
| 3 | 0.0833 | 0.1000 | 0.2000 | 0.0500 |
| 4 | 0.0000 | 0.0167 | 0.0500 | 0.2500 |
| CFk | 0.126519 | 0.135793 | 0.121803 | 0.039960 |
with β = 0.15 and γ = 1.
Exemplo de LOGIT
| Fator de Escala | P(1) | P(2) | P(3) | P(4) |
|---|---|---|---|---|
| 1 | 0.260448 | 0.256143 | 0.247746 | 0.235663 |
| 10 | 0.354498 | 0.300076 | 0.215014 | 0.130412 |
| 20 | 0.450502 | 0.322799 | 0.165730 | 0.060969 |
| 30 | 0.532071 | 0.322717 | 0.118721 | 0.026490 |
| 40 | 0.599856 | 0.307976 | 0.081182 | 0.010987 |
| 50 | 0.656417 | 0.285278 | 0.053882 | 0.004423 |
| 60 | 0.704153 | 0.259044 | 0.035058 | 0.001745 |
| 100 | 0.836359 | 0.157968 | 0.005635 | 0.000038 |
| 500 | 0.999760 | 0.000240 | 1.3885E-11 | 1.9283E-22 |
| 1000 | 1 | 0 | 0 | 0 |
| 2000 | 1 | 0 | 0 | 0 |
| 3600 | 1 | 0 | 0 | 0 |
Exemplo de C-LOGIT
| Fator de Escala | P(1) | P(2) | P(3) | P(4) |
|---|---|---|---|---|
| 1 | 0.280102 | 0.240493 | 0.235886 | 0.243519 |
| 10 | 0.608338 | 0.132440 | 0.109147 | 0.150074 |
| 20 | 0.876849 | 0.041560 | 0.028227 | 0.053364 |
| 30 | 0.969831 | 0.010007 | 0.005601 | 0.014561 |
| 40 | 0.993062 | 0.002231 | 0.001029 | 0.003678 |
| 50 | 0.998414 | 0.000488 | 0.000186 | 0.000912 |
| 60 | 0.999635 | 0.000106 | 0.000033 | 0.000225 |
| 100 | 0.999999 | 0.000000 | 0.000000 | 0.000001 |
| 500 | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 1000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 2000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 3600 | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
| 4000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 |
O parâmetro de fator de escala, θ, e os parâmetros de fator de comunalidade, β e γ, podem ser definidos via aba de parâmetros de Escolha de Rota quando o modelo C-Logit é selecionado.
Modelo de Escolha de Rota Definido pelo Usuário¶
Como alternativa aos Modelos de Escolha de Rota padrão, podem ser usados Modelos de Escolha de Rota definidos pelo usuário. Isso é feito usando o Cost Function Editor. Consulte o Funções seção para obter mais informações sobre a definição das funções de custo.
Determinar o conjunto finito de caminhos no processo de decisão¶
A seleção de caminhos baseada em modelos discretos de escolha de rota estima as taxas de fluxo de caminho de um conjunto finito de caminhos alternativos \(K_{i}\), conectando o i-ésimo par OD, e esse conjunto de caminhos alternativos é atualizado considerando as árvores de caminho mínimo calculadas a cada intervalo da Dynamic Traffic Assignment.
No intervalo de tempo \(t\), o algoritmo de caminho mínimo é aplicado e gera a árvore de caminhos mínimos \(SPT_{d}(t)\) por cada centroide de destino d∈D. Então, para cada par OD i∈I (com centroide de origem o e centroide de destino d) e tomando \(SPT_{d}(t)\) ele gera um caminho \(SPT_{con}(t)\) para cada conexão \(con\) vinculado ao centroide de origem.
O processo para determinar o conjunto finito de caminhos a ser usado no processo de decisão recebe como parâmetro o "MaxNumberToKeep (que representa o número máximo dos caminhos mínimos mais recentes a considerar), MaxNumberOfRoutes (que representa o número máximo de caminhos diferentes) e UseBestEntrance da origem do centroide.
O algoritmo é o seguinte:

Quando a opção de centroide de origem Usar Percentuais de Origem é selecionada, cada conexão é considerada independentemente das outras, atribuindo a cada conexão a porcentagem da demanda gerada pelo centroide e aplicando o modelo de escolha de rota para cada conexão.
Atribuição inicial¶
A Atribuição Inicial é o processo de seleção de caminho quando um veículo entra no sistema. Ela corresponde à Etapa 1 no algoritmo genérico de Atribuição Dinâmica de Tráfego.
Um veículo do tipo de veículo \(vt\) viajando do par OD \(i\), pode escolher um caminho de acordo com a atribuição definida pelo usuário ou como resultado de um modelo de Escolha de Rota a partir do conjunto de caminhos alternativos \(K_{i}\):
- N Rotas OD: \(ODR_{n}\)^i^ n=1..N*
- M Caminho a partir dos resultados de Atribuição: \(PAR_{m}\)^i^ m=1..M*
- P Caminhos mínimos iniciais: \(ISP_{p}\)^i^ , p=1..M
- Q Caminhos Mais Curtos Atualizados em Tempo Hábil: \(DSP_{q}\)^i^, q=1..Q*
A atribuição inicial é determinada pela porcentagem de uso das rotas OD (%\(ODR_{vt}\)) e a porcentagem de uso de um Resultado de Atribuição de Caminhos (%\(PAR_{vt}\)) (pode ser determinado por tipo de veículo e definido nos parâmetros de Route Choice):
Definindo as seguintes funções:



Então o algoritmo de Atribuição Inicial é definido como:

Como exemplo:
Assume that for one vehicle type vt:
%ODR = 40%
%PAR = 70%
Assume there are two OD Routes defined with the %use:
P(ODR1) = 10%
P(ODR2) = 50%
Assume there are two paths from a Assignment result with %use
P(PAR1) = 30%
P(PAR2) = 70%
Assume there are three calculated paths and the Route Choice model assigns %use:
P(DSP1) = 30%
P(DSP2) = 20%
P(DSP3) = 50%
Then the final percentages of vehicle type vt assigned to each path are:
ODR1 = 40% * 10%
ODR2 = 40% * 50%
The vehicles not assigned to one ODR then:
PAR1 = [(1- 40%) + (40% *(1-10%-50%)] * 70% * 30%
PAR2 = [(1- 40%) + (40% *(1-10%-50%)] * 70% * 70%
The vehicles not assigned to either one ODR or one PAR then:
DSP1 = [(1- 40%)+ (40% *(1-10%-50%)] * (1-70%) *30%
DSP2 = [(1- 40%)+ (40% *(1-10%-50%)] * (1-70%) * 20%
DSP3 = [(1- 40%)+ (40% *(1-10%-50%)] * (1-70%) *50%
Atualização de Alocação de Caminhos Em Rota ¶
Os veículos são inicialmente atribuídos a um caminho a partir de um conjunto de caminhos disponíveis com base em probabilidade. Após a atribuição inicial, que é feita no momento da partida do veículo, existe a possibilidade de fazer uma reatribuição de caminho durante a viagem (En-Route Path Update).
A atualização En-Route Path Assignment corresponde à Etapa 3 no algoritmo genérico de Dynamic Traffic Assignment e é aplicada quando o Atualização de Caminho em Rota parâmetro é selecionado na pasta Dynamic Traffic Assignment no editor do experimento.
A atualização da atribuição de caminhos em rota é determinada pelo percentual de atualização da atribuição de caminhos em rota dos veículos que seguem uma rota OD (%\(ERODR_{vt}\)), a porcentagem de atualização da alocação de caminhos em rota dos veículos que seguem um caminho resultante de um resultado de alocação (%\(ERPAR_{vt}\)) e a porcentagem de atualização de alocação de caminhos em rota de veículos que seguem um caminho atribuído pelo modelo Route Choice (%\(ERRCM_{vt}\)) (pode ser determinado por tipo de veículo e definido na aba Parâmetros de Escolha Estocástica de Rotas:

Caminho Alocado Após Fila Virtual¶
Esta opção pode ser usada para reatribuir o caminho para todos os veículos que estão em uma fila virtual. A reatribuição é calculada a cada intervalo de tempo de escolha de rota. Está disponível apenas para simulações SRC.
decisão de Seção de Entrada/Saída¶
Quando o modelo de escolha de rota é aplicado a um veículo na atribuição inicial, o primeiro passo é decidir a seção de entrada pela qual o veículo entrará no sistema e a seção de saída pela qual ele sairá. Essa decisão é tomada considerando o uso de percentuais no centroide de origem e de destino (atributo do centroide). Há 4 situações diferentes:
Centroide de Origem considera Percentuais / Centroide de Destino considera Percentuais¶
O exemplo na figura abaixo demonstra o processo de decisão. Aqui, o centroide de origem tem 3 conexões (A, B e C) com carregamento atribuído de 30%, 20% e 50%, respectivamente, e o centroide de destino tem 3 conexões de saída (X, Y e Z) com 40%, 10% e 50%. As únicas combinações viáveis que a conectividade da rede permite são que, a partir da conexão B, é possível alcançar as conexões X, Y e Z, enquanto a partir da conexão C é possível alcançar as conexões Y e Z.
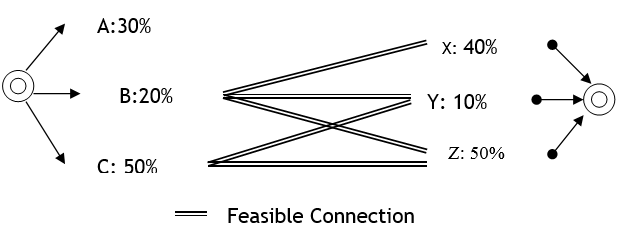
A primeira etapa é decidir a seção de entrada. Esse processo leva em conta apenas as conexões viáveis disponíveis para alcançar o destino e recalcula as porcentagens considerando a porcentagem original sobre a soma das porcentagens de todas as conexões viáveis. Neste exemplo, o valor para A é 0% (não viável), B é 20%/70% (70% é a soma de 20% e 50%) e C é 50%/70%. Usando essas porcentagens calculadas como probabilidades, o veículo escolhe a conexão, isto é, a seção de entrada, que usará.
Depois que a seção de entrada é selecionada, a seção de saída é escolhida. Isso é feito considerando apenas as conexões viáveis a partir da seção de entrada selecionada e recalculando as porcentagens como a porcentagem original sobre a soma das porcentagens de todas as conexões viáveis. Neste exemplo, se a seção de entrada escolhida usa a conexão C, então a probabilidade calculada da conexão X será 0% (não viável a partir da conexão C), Y será 10%/60% (60% é a soma de 10% e 50%) e Z será 50%/60%. O veículo então escolhe a seção de saída usando essas probabilidades.
Centroide de Origem considera Percentuais / Centroide de Destino não considera Percentuais¶
Neste caso, a seção de entrada é selecionada como no caso anterior e a seção de saída depende do caminho mais curto.
Centroide de Origem não considera Percentuais / Centroide de Destino considera Percentuais¶
Neste caso, a seção de saída é selecionada como no caso anterior, considerando apenas as conexões viáveis a partir da origem. A seção de entrada é selecionada considerando o modelo de escolha de rota.
O Usar Melhor Entrada O parâmetro define se o algoritmo de escolha de rota levará em conta, para cada centroide de origem e para cada cálculo, apenas o caminho mais curto a partir da entrada com o menor custo (Usar Melhor Entrada marcado) ou um caminho mais curto a partir de cada seção de entrada (Usar Melhor Entrada não marcada).
Centroide de Origem não considera Porcentagens / Centroide de Destino não considera Porcentagens¶
A seção de entrada e a seção de saída são selecionadas considerando o modelo de escolha de rota.
O Usar Melhor Entrada O parâmetro define se o algoritmo de escolha de rota levará em conta, para cada centroide de origem e para cada cálculo, apenas o caminho mais curto a partir da entrada com o menor custo (Usar Melhor Entrada marcado) ou um caminho mais curto a partir de cada seção de entrada (Usar Melhor Entrada não marcada).