Métodos Estatísticos para Validação de Modelos¶
Os métodos e técnicas estatísticos para validar modelos de simulação são claramente explicados em muitos livros-texto e artigos especializados Law e Kelton 1991, Balci 1998 e Kleijnen 1995. Esta seção demonstra a adaptação do processo geral ao problema de validar um modelo de simulação dinâmica.
Os dados medidos da rede viária devem ser divididos em dois conjuntos de dados independentes: o conjunto de dados que será usado para desenvolver e calibrar o modelo, e um conjunto de dados separado que será usado na validação. Esses dois conjuntos de dados podem ser dados diferentes (isto é, calibrar o modelo com contagens de fluxo e de movimentos de conversão, validá-lo com tempos de viagem) ou podem ser subconjuntos dos mesmos dados (isto é, calibrar o modelo com um conjunto de fluxos e validá-lo com outro).
Em cada passo de um processo iterativo de validação, será conduzido um experimento de simulação. Cada um desses experimentos de simulação será definido pelos dados de entrada do modelo de simulação e pelo conjunto de valores dos parâmetros do modelo que identificam o experimento. Eles serão ajustados para calibrar o modelo. A saída do experimento de simulação será um conjunto de valores simulados das variáveis de interesse, neste caso os fluxos medidos em cada detector de tráfego na rede viária em cada intervalo de amostragem.
Por exemplo: assumindo que, no experimento de simulação, as estatísticas do modelo sejam coletadas a cada cinco minutos (o intervalo de amostragem) e que a variável amostrada seja o fluxo simulado \(w\). Então a saída do modelo de simulação será caracterizada pelo conjunto de valores \(w_{ij}\), do fluxo simulado no detector \(i\) no instante \(j\), onde o índice \(i\) identifica o detector e o índice \(j\) o intervalo de amostragem. Se \(v_{ij}\) são as medidas reais correspondentes para o detector \(i\) no intervalo de amostragem \(j\), uma técnica estatística típica para validar o modelo seria comparar ambas as séries de observações para determinar se elas estão suficientemente próximas. Para cada detector \(i\) a comparação poderia ser baseada em testar se a diferença ao longo dos intervalos de tempo \(j\) (1 to \(m\)):
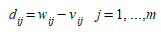
tem uma média significativamente diferente de zero ou não. Isso pode ser determinado usando a estatística t:
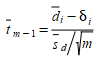
para testar a hipótese nula:
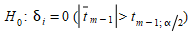
onde δ\(_{i}\) é o valor esperado de \(d_{i}\) e \(s_{i}\) é o desvio padrão de \(d_{i}\).
-
Se para δ\(_{i}\) = 0 o valor calculado \(t_{m-1}\) do Estudante \(t\) distribuição for significativa para o nível de significância especificado α, então devemos concluir que o modelo não está reproduzindo de perto o comportamento do sistema e, portanto, devemos melhorar o modelo.
-
Se δ\(_{i}\) = 0 fornece um não significativo \(t_{m-1}\) então concluímos que o modelo está reproduzindo adequadamente o comportamento do sistema e podemos aceitar o modelo.
Esta avaliação será repetida para cada uma das n detectores. O modelo é aceito quando todos os detectores, ou um subconjunto específico de detectores dependendo dos objetivos do modelo, passam no teste
No entanto, no que diz respeito ao método estatístico, há algumas considerações especiais a serem levadas em conta especificamente no caso da análise de simulação de tráfego (Kleijnen 1995).
-
O procedimento estatístico assume observações identicamente e independentemente distribuídas (i.i.d), enquanto as medições reais do sistema e a saída simulada correspondente para uma série temporal podem não seguir essa premissa. Portanto, seria desejável que pelo menos as m diferenças pareadas (correlacionadas) \(d_{i}\) = \(w_{ij}\) – \(v_{ij}\), \(j\)=1,…,\(m\) são (i.i.d). Isto pode ser alcançado quando o \(w_{ij}\) e o \(v_{ij}\) são valores médios de experimentos replicados independentemente.
-
Quanto maior a amostra, menor o valor crítico
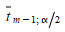 é, e isso implica que um modelo de simulação tem maior chance de ser rejeitado à medida que a amostra aumenta. Portanto, o t as estatísticas podem ser significativas e, ainda assim, sem importância se a amostra for muito grande, e o modelo de simulação pode ser bom o suficiente para fins práticos.
é, e isso implica que um modelo de simulação tem maior chance de ser rejeitado à medida que a amostra aumenta. Portanto, o t as estatísticas podem ser significativas e, ainda assim, sem importância se a amostra for muito grande, e o modelo de simulação pode ser bom o suficiente para fins práticos.
Essas considerações implicam que não é prudente depender de apenas um tipo de teste estatístico para validar o modelo de simulação. Um teste alternativo é verificar se \(w\) e \(v\) são positivamente correlacionados, isto é, testar a significância da hipótese nula:
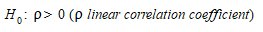
Isso representa um teste de validação menos rigoroso, aceitando que as respostas reais simuladas não tenham necessariamente a mesma média e que o que é significativo é se elas estão positivamente correlacionadas ou não. O teste pode ser implementado usando a técnica de mínimos quadrados ordinários para estimar o modelo de regressão:
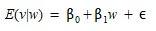
onde ε é um termo de erro aleatório.
O teste diz respeito à hipótese unilateral \(H_0\): β\(_1\) ≥ \(0\) A hipótese nula é rejeitada e o modelo de simulação é aceito se houver fortes evidências de que as respostas simuladas e reais estão positivamente correlacionadas. A análise de variância do modelo de regressão é a forma usual de implementar este teste. Este teste pode ser reforçado, tornando-se equivalente ao primeiro teste se esta hipótese for substituída pela hipótese composta \(H_0\): β\(_0\) = 0, and β\(_1 = 1\) implicando que as médias das medições reais e das respostas simuladas são idênticas e, quando uma medição do sistema excede sua média, a observação simulada também excede sua média.
Comparação das duas séries \(v_{ij}\) e \(w_{ij}\) para intervalos de tempo \(j=1,...,m\) pode ser obtido com medidas RMSPE (Root Mean Square Percent Error), U de Theil ou a estatística GEH.
RMSPE¶
Se, para o detector \(i\) o erro de previsão no intervalo de tempo \(j\) (\(j=1,...,m\)) é \(d_{ij}\) = \(w_{ij}\) – \(v_{ij}\), então uma forma comum de estimar o erro das previsões para o detector \(i\) é "Root Mean Square Percent Error".
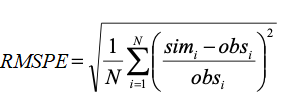
Esta estimativa de erro talvez tenha sido a mais usada em simulação de tráfego e, embora obviamente quanto menor o valor de \(rmspe_i\) melhor o modelo, ele tem uma desvantagem bastante significativa, pois eleva o erro ao quadrado, enfatizando assim erros grandes.
U de Theil¶
Estatística U de Theil (Theil 1966) é uma medida de associação entre duas séries em que um valor de 0 implica que não há diferença entre os dados observados e simulados, e um valor de 1 implica que não há relação entre os dados observados e simulados.
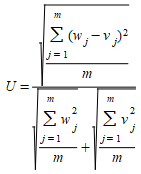
O U de Theil pode ser decomposto para quantificar três tipos diferentes de erro.
O Proporção de viés \(U_m\) é uma medida do erro sistemático na simulação (a diferença líquida) e é definido como
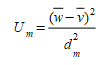
O Proporção da variância \(U_s\) é uma medida da capacidade da simulação de reproduzir a variabilidade nos dados observados com base na diferença entre o desvio padrão nas duas séries e é definida como:
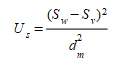
O Proporção de covariância \(U_c\) é uma medida do erro não sistemático na simulação ou da falta de correlação entre as séries e é definido como:
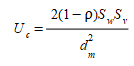
em que \(d^2_m\) é o erro médio quadrático de previsão (\(RMS^2\)) \(S_w\) e \(S_v\) são os desvios-padrão amostrais das duas séries, e ρ é o coeficiente de correlação amostral entre elas.
A melhor previsão é aquela em que \(U_m\) e \(U_s\) estão próximos de 0 e \(U_c\) é próximo de 1.
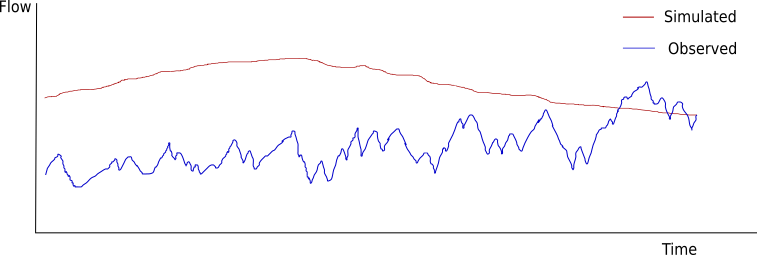
A figura abaixo demonstra um ajuste ruim por três motivos:
- A média das duas séries é diferente (\(U_m\)).
- A variância nas duas séries é diferente (\(U_s\)).
- A covariância é baixa (\(U_c\)), as subidas e descidas sistemáticas nos fluxos não são correlacionadas.
GEH¶
O GEH A estatística é usada para comparar volumes de tráfego. Seu nome deriva de seu inventor, Geoffrey E. Havers, e é usada como critério de aceitação para modelos de previsão de demanda de viagens pelas diretrizes UK WebTAG, nas quais é fornecido um conjunto de limiares de aceitabilidade; um valor GEH inferior a 5 é considerado um bom ajuste, entre 5 e 10 implica que o local de medição justifica investigação quanto a erro, e um valor maior que 10 implica um erro significativo e inaceitável. Como a medida é não linear, um único conjunto de limiares de aceitação pode ser especificado para uma ampla faixa de valores de fluxo.
A estatística GEH é definida como:
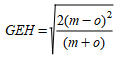
Onde m é o fluxo horário modelado e o o fluxo observado.
GEH deve ser aplicado somente a fluxos horários, ou a fluxos ajustados para valores de 1 hora.
No Aimsun Next, a estatística GEH Discrete classifica o valor GEH, principalmente para exibição, para identificar áreas problemáticas. Os valores são:
- GEH < 5: Bom ajuste - valor 0.
- GEH 5 - 10 e Observado < Resultado: Requer investigação, muito alto - valor 1.
- GEH > 10 E Observado < Resultado: Inaceitável, muito alto - valor 2.
- GEH 5 - 10 e Observado > Resultado: Requer investigação, muito baixo - valor 3.
- GEH > 10 E Observado > Resultado: Inaceitável, muito baixo - valor 4.